Nov 14, 2025
What's behind the text box — how LLMs work, simply explained
You type something into ChatGPT. Hit enter. Something smart comes back. But what just happened? What are you actually talking to? Most people have no idea. And most explanations either drown you in math or hand-wave with "it's AI." Here's the version that actually makes sense.
1. It starts by eating the internet
Before any "intelligence" happens, someone collects billions of web pages.
Then they filter aggressively. No spam. No junk. No ads. Just clean text.
What's left is basically a compressed copy of the readable internet. One massive pile of human knowledge.
That's the raw material. Nothing more.

2. Tokens: the atoms of language models
This is where most people's mental model breaks.
LLMs don't see words like you do. They chop text into small chunks called tokens. "Hello world" is two tokens. "Strawberry" is three.
GPT-4 has about 100,000 possible tokens. Think of each one like a unique puzzle piece.

Why this matters: the model literally can't see individual letters. That's why it couldn't count the R's in "strawberry" for months. It doesn't perceive the word at that level.
3. The core idea is stupidly simple
Take a window of tokens from the training data. Feed them into a neural network. The network outputs a probability for every single possible next tokens.
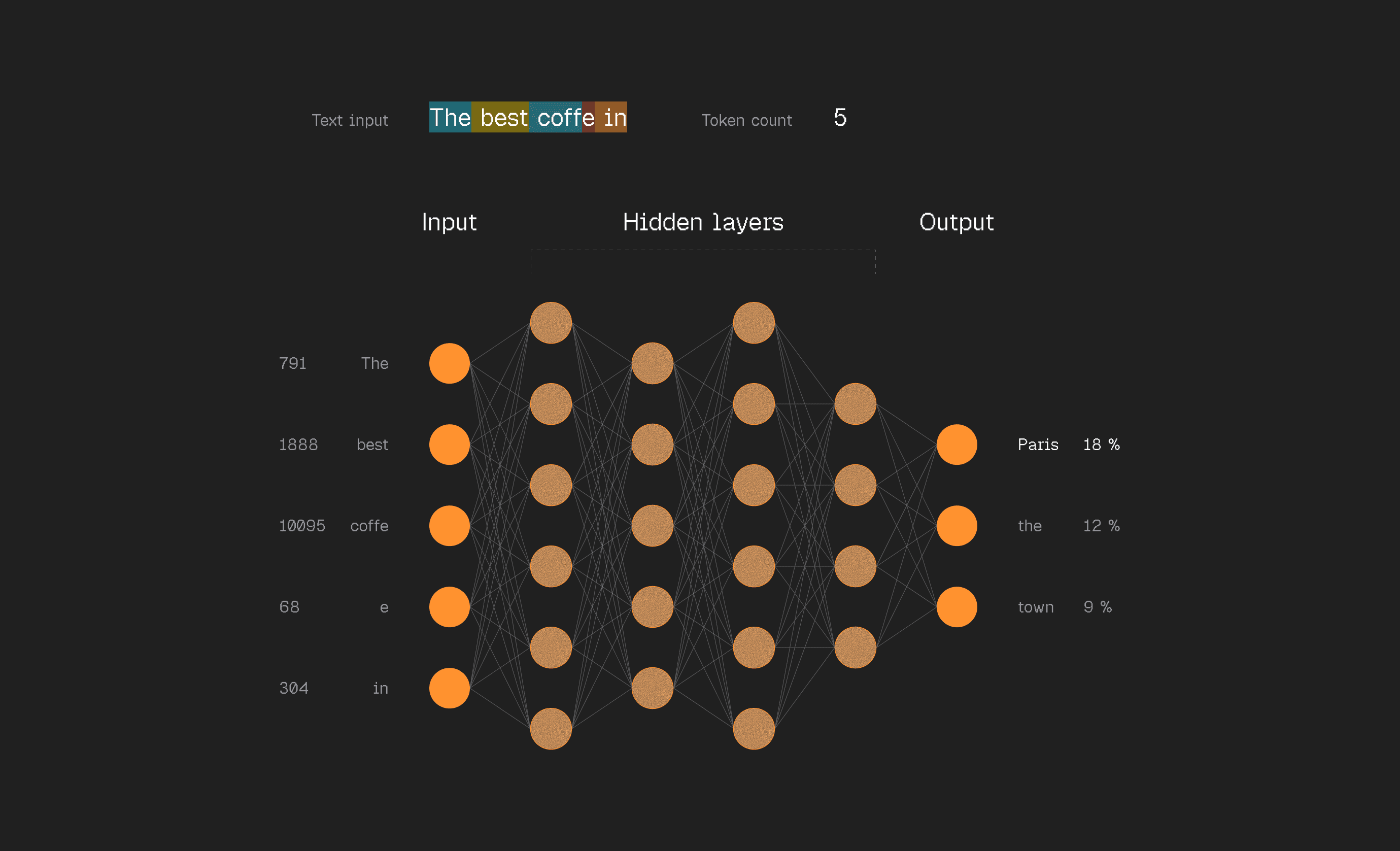
At first, it's terrible. Random guesses. But we know the right answer, it's in the training data. So we nudge the model to make the right guess more likely, everything else less likely.
Do this billions of times across the entire internet's worth of text.
The result is called a base model. And here's what most people miss. A base model is NOT an assistant. It doesn't answer questions. It doesn't try to help you. It's an internet document simulator, a very expensive autocomplete.
Useful? Not directly. But in learning to predict internet text, this thing has absorbed an insane amount of knowledge into its parameters. Think of it as a lossy compression of the internet, not a perfect copy, but a statistical echo of everything it read.
4. Then you teach it to be helpful
To get an actual assistant, you fine-tune it on conversations.
Human labelers write thousands of ideal responses to all kinds of prompts.
Train on this data and the model shifts from simulating random web pages to simulating a helpful assistant.
So what are you actually talking to in ChatGPT?
A neural network simulation of what a skilled human labeler would write. Following the company's guidelines. For your specific question.
Not a magical AI. A statistical imitation of a well-trained human.
Let that satisfyingly sink in for a moment.
5. Then it learns to think
Give the model problems with known answers. Let it try thousands of solutions. Some work, some don't. Reinforce the ones that work.
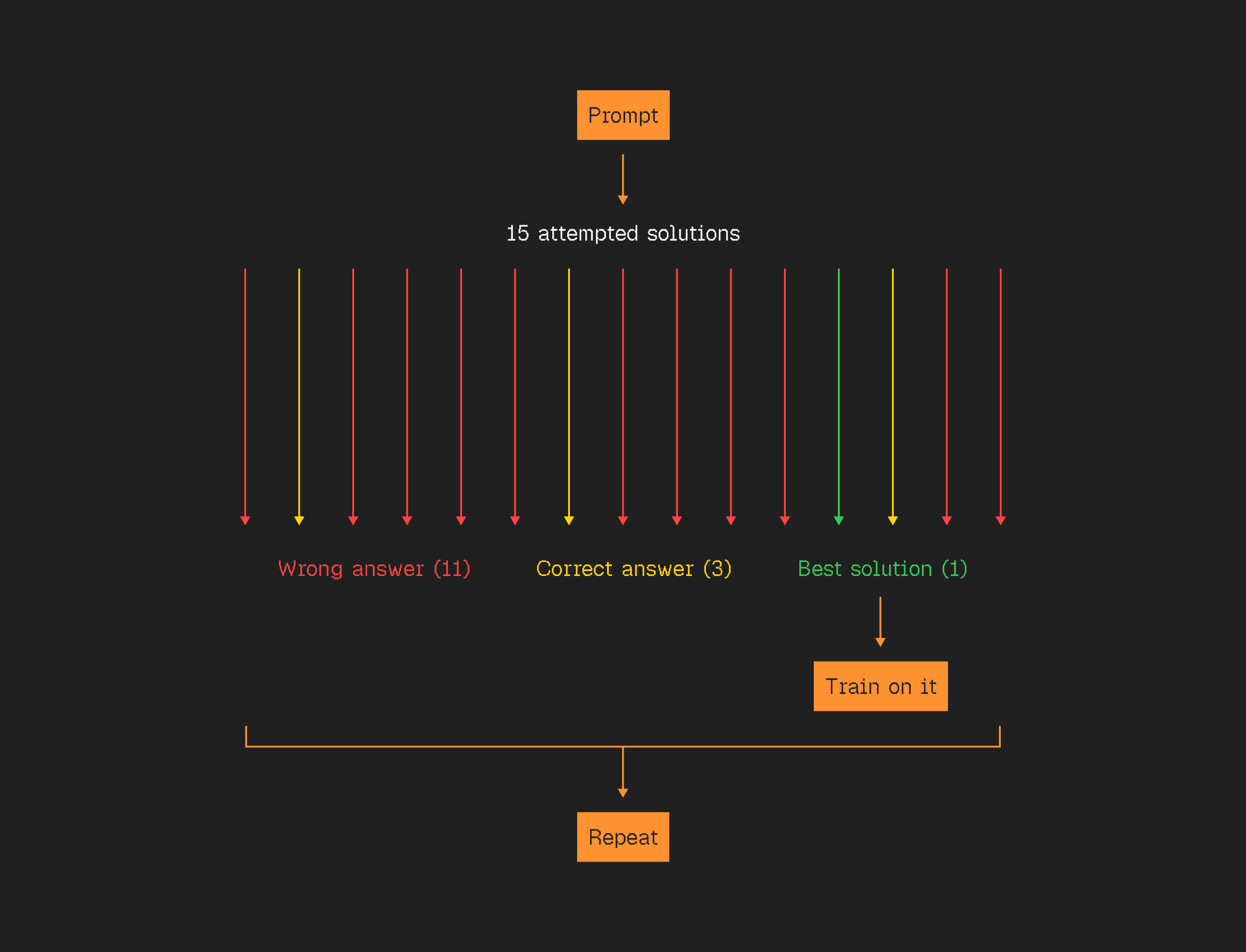
Over time, something crazy emerges. The model starts to backtrack. Double-check its work. Try different approaches. Rethink assumptions.
Nobody programmed this. It discovered these thinking strategies on its own because they lead to correct answers.
This is what "thinking models" do. They're not just copying human experts anymore. They're developing reasoning from scratch.
The takeaway
Use it as a tool, not an oracle.
What comes back when you hit enter is remarkable. But it's a statistical simulation.
Knowing that makes you 10x better at using it.
Use
for navigation.